Spark 개념, docker로 cluster 환경 구축하기
이번 포스팅에서는 Spark에 대한 간단한 개념을 알아보고, 클러스터 환경을 구축해보겠습니다.
Apache Spark?
Apache Spark는 빅데이터 처리를 위한 고속 분산 처리 엔진입니다.
Hadoop의 MapReduce가 등장하고 이전에는 처리할 수 없었던 대량의 데이터를 처리할 수 있게 되었습니다. 하지만 MapReduce는 극복하지 못한 한계가 있습니다.
Hadoop은 Disk기반이기 때문에 자원을 할당, 해제하고, 데이터를 입출력하는 데에 너무 오랜 시간이 걸린다는 것이였습니다.
이때문에 데이터 처리 시간보다 부가적인 작업에 의해 시간과 자원의 낭비가 심하다는 한계가 있었습니다.
Spark는 분산 데이터 모델인 RDD와 in-memory 기반으로 Hadoop MapReduce의 한계를 극복했고, MapReduce보다 100배 빠른 성능을 보였습니다.
Spark Cluster
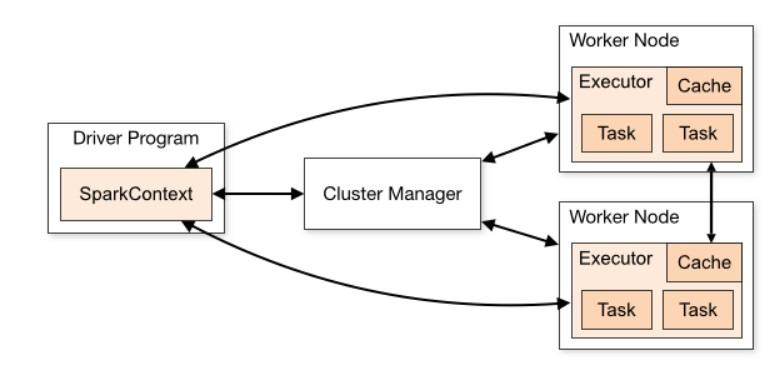
Spark Driver
Spark 프로그램의 중앙처리장치로, ~인 Spark Context를 실행합니다. 쉽게 말해 작업하는 환경으로 Script를 작성하는 곳입니다.
Executor
할당된 task가 실제로 수행되는 worker입니다.
Cluster Manager
Spark Driver가 task를 수행할 executor를 요청하면, 가용한 자원을 할당해줍니다. 또한 성능을 트래킹하고 만약 작업중이 node가 작업을 실패하거나 죽으면 다른 노드를 할당해서 작업이 중지되지 않도록 관리합니다.
클러스터 환경 구축하기
1. Dockerfile 작성
ubuntu 기반의 Spark 환경을 구축하는 Dockerfile입니다.
Dockerfile을 직접 작성해도 되고, 아래 이미지를 사용해도 됩니다.
docker.io/bitnami/spark:3.2.4# ubuntu:18.04 이미지를 기반
FROM ubuntu:18.04
# 패키지 목록 업데이트
RUN apt-get update
# 패키지와 java11 JDK, python3 패키지 관리자 pip 설치
RUN apt-get -y install wget ssh curl openjdk-11-jdk python3-pip
# RUN ls /usr/lib/jvm/java-11-openjdk-arm64/bin
# pip으로 pyspark 설치
RUN pip3 install pyspark
# 작업 디릭토리 변경 - spark 관련 명령어 작업 실행
WORKDIR /opt/spark
# spark 다운로드
RUN wget https://dlcdn.apache.org/spark/spark-3.5.4/spark-3.5.4-bin-hadoop3.tgz
# 압축 해제
RUN tar -zxvf spark-3.5.4-bin-hadoop3.tgz
# 압축파일 삭제
RUN rm spark-3.5.4-bin-hadoop3.tgz
# 설치 경로를 환경 변수에 설정
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-arm64
ENV HADOOP_HOME=/opt/hadoop/hadoop-3.3.6
ENV SPARK_HOME=/opt/spark/spark-3.5.4-bin-hadoop3
# PySpark에서 사용할 Python 버전을 설정
ENV PYSPARK_PYTHON=/usr/bin/python3
# Spark의 실행 파일들이 포함된 sbin 디렉토리를 PATH 환경 변수에 추가하여, 터미널에서 spark-submit과 같은 Spark 명령어를 사용할 수 있도록.
ENV PATH="$PATH:/opt/spark/spark-3.5.4-bin-hadoop3/sbin"
# Spark가 데몬 모드로 실행되지 않도록 설정합니다. 기본적으로 Spark는 클러스터에서 백그라운드로 실행되는데, 이 옵션을 사용하면 포그라운드에서 실행되도록 할 수 있습니다. 주로 디버깅에 유용합니다.
ENV SPARK_NO_DAEMONIZE=true
2. Docker-compose 작성
# 하둡 컨테이너와의 통신을 위해 같은 네트워크를 사용하도록 함
networks:
hadoop-spark-network:
external: true # 외부 네트워크 사용
services:
master:
container_name: master
image: qufdl/my-spark:1.0
networks:
- hadoop-spark-network
ports:
- "8080:8080" # Spark Master UI
- "7077:7077" # Spark Master Port
command: start-master.sh # Master 컨테이너는 Master 프로세스만 실행
worker-1:
container_name: worker-1
image: qufdl/my-spark:1.0
networks:
- hadoop-spark-network
depends_on:
- master
ports:
- "8081:8081" # Worker 1 UI
command: start-worker.sh spark://master:7077
worker-2:
container_name: worker-2
image: qufdl/my-spark:1.0
networks:
- hadoop-spark-network
depends_on:
- master
ports:
- "8082:8081" # Worker 2 UI (UI 포트는 컨테이너 내에서는 8081로 같지만, 외부에서는 8082로 접근)
command: start-worker.sh spark://master:7077
Dockerfile을 빌드한 후에, compose를 실행시키면, 스파크 클러스터가 구축됩니다.