-
[Database] Index에 대해서CS/DataBase 2024. 11. 18. 06:24
인덱스란?
인덱스란, 데이터베이스에서 데이터를 조회할 때 결과를 빠르게 추출하도록 도와주는 하나의 '데이터베이스객체’이다.
인덱스 사용법
CREATE INDEX [인덱스 이름] ON [테이블 명(컬럼 명)]Ex)
-- 테이블 예시 CREATE TABLE products ( id INT AUTO_INCREMENT PRIMARY KEY, name VARCHAR(100), category VARCHAR(50), price DECIMAL(10, 2), stock INT, created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP );CREATE INDEX product_category ON products (category); -- 인덱스 생성SHOW INDEX FROM products; -- 생성된 인덱스 확인
생성된 인덱스 인덱스 활용
인덱스 단점
1. 삽입, 수정, 삭제 시 성능 저하
삽입, 수정, 삭제 작업이 발생할 때마다 인덱스가 함께 업데이트되어야 하므로, 이 과정에서 추가적인 연산이 필요하다.
2. 추가적인 저장 공간 소모
인덱스는 테이블 데이터 외에도 별도의 저장 공간을 차지 (약 DB의 10%)
3. 인덱스가 필요하지 않은 쿼리에 오히려 성능 저하
특정 쿼리들이 인덱스보다 테이블을 직접 스캔하는 것이 더 빠른 경우도 있다.
인덱스를 사용하면 좋은 컬럼
1. WHERE 절이나 JOIN 조건에 자주 사용되는 컬럼
2. ORDER BY나 GROUP BY 절에 자주 사용되는 컬럼
3. JOIN 연산이 자주 사용되는 컬럼(특히 외래키)
4. 데이터가 적지 않은 테이블
5. Cardinality가 높고, Selectivity가 낮고, 활용도가 높은 컬럼
Cardianlity
특정 컬럼의 고유한 값의 개수를 의미.
컬럼 값에 중복이 많으면 Cardinality가 낮다고 하고, 중복이 적으면 Cardinality가 높다고 한다.
ex) 주민등록번호 -> 중복도 낮음 = Cardinality 높음
❓왜 Cardinality가 높으면 인덱스에 적합할까?
인덱스를 사용했을 때 원하는 데이터를 빠르게, 그리고 적은 양만 가져올 수 있기 때문.
카디널리티가 높은 컬럼에 인덱스를 사용하면, 특정 값을 찾을 때 조회 대상이 빠르게 줄어든다.
예를 들어, 주민등록번호로 한 사람을 찾을 때는 바로 그 사람의 데이터만 가져오게 됨.
Selectivity
데이터에서 특정 값을 얼마나 잘 선택할 수 있는지에 대한 지표
5~10% 정도가 적당
계산 방법
= 컬럼의 특정 값의 row 수 / 테이블의 총 row 수 * 100
= 컬럼의 값들의 평균 row 수 / 테이블의 총 row 수 * 100
❓ 왜 Selectivity가 낮으면 인덱스에 적합할까?
선택도가 높으면, 인덱스를 사용해도 반환되는 행이 많아 풀 스캔과 비슷하게 된다.
하지만 (논클러스터)인덱스는 풀스캔에 비해 데이터를 찾을 때 작업이 더 많기 때문에 오히려 성능 저하를 일으킬 수 있다.
활용도
해당 컬럼이 실제 작업에서 얼마나 활용되는지에 대한 값 = 자주 사용되는 컬럼
자주 사용되는 컬럼에 인덱스를 걸면, 인덱스가 없을 때에 비해 디스크 I/O가 감소되기 때문
인덱스 구조
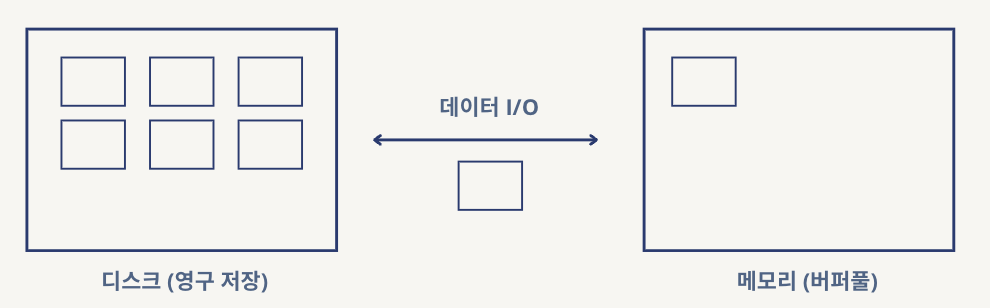
페이지 (Page)
디스크와 메모리(버퍼풀)에 데이터를 읽고 쓰는 최소 작업 단위.
DB의 데이터는 영구저장을 위해 디스크에 저장돼있다가 사용자가 I/O 요청하면 버퍼풀이라는 메모리에 올려 사용한다.
이때 페이지 단위로 I/O가 이루어진다.
따라서 만약 쿼리를 통해 1개의 레코드를 읽고 싶더라도 결국은 하나의 블록을 읽어야 하는 것이다.
페이지에 저장되는 개별 데이터의 크기를 최대한 작게 하여, 1개의 페이지에 많은 데이터들을 저장할 수 있도록 하는 것이 상당히 중요.
B+tree Index vs Hash Index
B+Tree Index

1. 균형 트리 구조
- B-Tree는 모든 리프 노드가 같은 깊이를 유지하는 균형 트리로, 삽입과 삭제 시 트리의 높이가 일정하게 유지된다.
- 이로 인해, 탐색, 삽입, 삭제 연산의 시간 복잡도가 O(log n)으로 일정하게 유지된다.
2. 정렬된 데이터 저장
- B-Tree 인덱스는 데이터를 정렬된 상태로 유지하므로, 순차적 접근 및 범위 검색에 매우 효율적.
- 예를 들어, >=, <=, BETWEEN 등의 범위 조건에 매우 유리하다.
3. 노드(페이지)에 여러 개의 키와 포인터 저장
- 각 노드는 여러 개의 키 값을 저장하며, 자식 노드를 가리키는 포인터도 함께 저장.
- B-Tree는 높이를 줄이고 디스크 I/O를 줄이기 위해 한 노드에 다수의 키를 저장.
Hash Index

1. 정확한 값 비교에 최적화:
- 해시 인덱스는 값을 해시 함수로 변환하여 저장하므로, 특정 값의 동등 비교(=) 검색에서 매우 빠르다.
2. 범위 검색 비효율적:
- 해시 인덱스는 데이터가 정렬되지 않으므로 범위 검색(예: >, <, BETWEEN)이나 순차적 검색이 필요할 때는 적합하지 않다.
- 해시 함수가 생성한 해시 값은 데이터 순서를 보장하지 않기 때문
3. 빠른 검색 속도:
- 해시 인덱스는 해시 테이블을 기반으로 특정 값을 찾기 때문에, 조회 속도가 매우 빠르다.
- O(1)의 시간복잡도
4. 일부 스토리지 엔진에서만 지원:
- MySQL의 경우, 해시 인덱스는 MEMORY 스토리지 엔진에서만 기본적으로 지원합니다. InnoDB는 기본적으로 B-Tree 인덱스를 사용하므로, 해시 인덱스를 사용할 수 없습니다.
특징 BTree Hash 검색 최적화 동등, 범위 검색 모두 가능 동등(=)검색 최적화 범위검색 효율적 비효율적 정렬 정렬된 상태 유지 정렬되지 않음 충돌 없음 해시 충돌 가능성 존재 사용 엔진 거의 모든 엔진에서 지원 일부 엔진에서만 지원 ex) PostgreSQL 검색 속도 빠름 매우 빠름 저장 공간 노드 버켓 DBMS에서 B+tree 인덱스를 주로 사용하는 이유
범위 검색이 어려운 Hash Index에 비해, Btree Index는 범위 검색에 최적화 돼있고 정렬 구조이기 때문에, SQL DB에서 많이 사용된다.
데이터베이스별 기본 인덱스
SQL DB 기본 인덱스 방식 Hash 지원 여부 MySQL BTree MEMORY 엔진에서 지원 PostgreSQL BTree 지원함 Oracle BTree 직접 지원하지 않음 SQL server BTree 직접 지원하지 않음 MariaDB BTree MEMORY 엔진에서 지원 SQLite BTree 지원하지 않음 DB2 BTree 직접 지원하지 않음 NoSQL DB 기본 인덱스 방식 Amazon DynamoDB Hash Couchbase Hash MongoDB BTree CouchDB BTree Elasticsearch Inverted Index 왜 기본 인덱스 자료구조로 Btree가 사용될까?
1. 배열이나 연결리스트의 경우 순차 탐색을 해야한다.
2. Btree는 균형 이진트리로 Ologn의 시간복잡도를 보장해준다.
3. 균형 이진트리인 AVL이나 RedBlack은 노드 하나당 하나의 데이터만 저장 가능하다.
노드 간 연결은 포인터로 이루어져 있으므로, 트리 탐색 시 부모에서 자식 노드로 이동할 때마다 메모리 접근이 필요합니다. 이 과정에서 랜덤 액세스가 발생하며 디스크 I/O 비용이 증가한다.
AVL이나 RBT와 다르게 Btree는 하나의 노드에 여러 개의 키와 데이터를 저장할 수 있다. 따라서 탐색 중 노드 이동이 줄어들어 디스크 I/O 횟수가 감소된다.
4. B-tree가 아닌 B+tree인 경우 Leaf Node끼리 연결돼있다.
이로 인해 순차 탐색이 더 빠르게 이루어질 수 있다. 또한 Leaf 노드 간 연결 덕분에 범위 검색(range query)이 효율적이다.
인덱스 유형
Clustered Index
- 테이블당 하나만 존재.
- Leaf에 실제 데이터가 저장돼있음. (기본 테이블 = Clustered Index의 Lesf Node)
- 실제 데이터들이 클러스터드 인덱스에 의해서 정렬된 상태를 유지됨.
- Leaf Node에 실제 데이터가 저장돼있기 때문에, 랜덤 엑세스가 발생하지 않음.
인덱스 생성 기준
1. PK가 있을 경우 해당 컬럼에 클러스터드 인덱스 생성
2. UNIQUE가 있을 경우 해당 컬럼에 클러스터드 인덱스 생성
3. 둘 다 없을 경우 내부적으로 RowID를 이용해 인덱스 생성
Nonclustered Index
- 테이블당 여러개 존재 가능
- Leaf Node에는 인덱스 키값과 데이터의 RID가 저장돼있음.
- 인덱스 키값 자체는 정렬돼있지만, 실제 데이터 테이블과는 별개이므로 실제 데이터는 정렬된 상태가 아님
- Leaf Node까지 가서 RID를 찾은 후에 실제 데이터를 찾기 위해 다시 Clustered Index의 Root Node로 연결.
Clustered Non-Clustered 항상 Data 순서를 유지 Data 순서와 상관 X 한 테이블당 하나만 존재 (DBMS가 기본적으로 생성) 한 테이블에서 여러개 생성 가능 index를 저장할 추가적인 공간 X index를 저장할 추가적인 공간 필요 Data를 찾는데 추가적인 작업 X Data를 찾는데 추가적인 작업 필요 Composite Index
여러개의 컬럼으로 하나의 인덱스를 생성하는 것.
CREATE INDEX 인덱스명 ON 테이블명(컬럼1,컬럼2); -- 복합 인덱스 생성주의할 점
컬럼1 기준으로 정렬된 후에 컬럼2가 정렬된다.
따라서 컬럼2만 조회할 경우에는 결국 풀스캔이 일어나게 된다.
'CS > DataBase' 카테고리의 다른 글
트랜잭션 격리 수준 (0) 2025.02.23 SQL의 윈도우 함수 (with PARTITION BY) (2) 2025.02.17 CTE(Common Table Expression) (2) 2025.02.17 [DataBase] 트랜젝션 (2) 2024.12.02 [DataBase] 정규화, 반정규화 (3) 2024.11.25